
在Partial Domain Adaptation的问题中,为了实现部分域迁移的目标,大部分的研究采用的方法是利用一个“类级”的权重,来权衡分类器的损失,而pytorch中自带的交叉熵损失是不支持为交叉熵损失添加权重机制的(pytorch自带的cross_entropy函数中的weight是用来解决样本不平衡问题的,而不是解决部分域迁移的,这个weight与我们这里提到的weight不同)。

上图中ns为样本的数量,ys为类别的数量,p为预测概率,wk为类级的权重,用来削弱outlier class对于域迁移的影响。(outlier class的权重w会小一些,shared class的权重会大一些,这样分类器就会更加的关注于shared class的处理),具体的w计算方法各个研究不尽相同,大部分研究的核心就是关注于如何设置权重w的大小。
对于类级权重,计算得到的权重是一个行向量,长度为类别的数量(举个🌰:类别有五类,w = [0.5,0.6,0.7,0.1,0.2])
接下来的任务就是,对于这样的任务,我们该如何设置损失函数,来计算损失,从而完成神经网络的更新工作?

假设我们已经计算得到了分类器输出p{ batch_size , class_num },权重w{ class_num },ground truth{batch_size},现在我们进入类的设计:
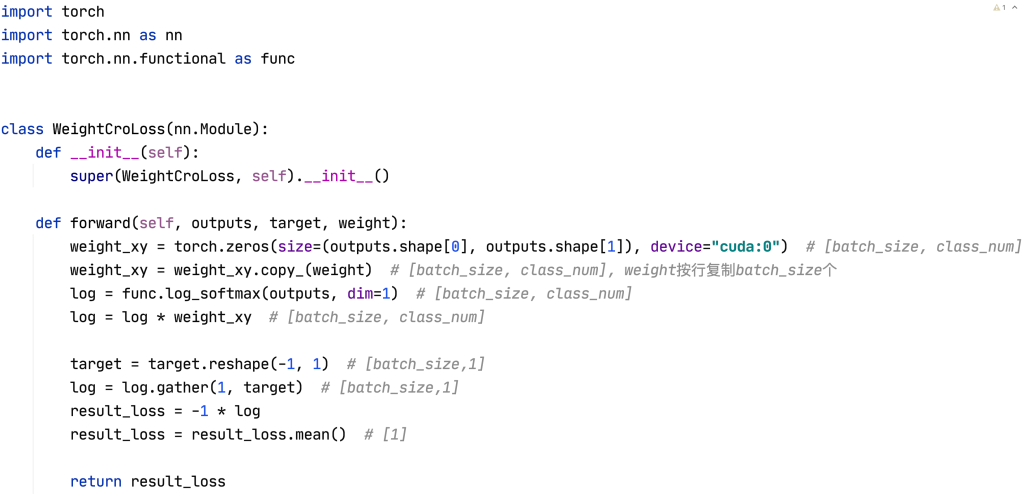
自定义计算损失的类,要继承自Module,并实现forward和__init__两个函数,才能在pytorch中进行梯度的计算反传(backward),这里的格式记住就可以,是pytorch中要求的。forward的参数:outputs代表分类器的输出(这里的输出没有经过softmax和log的处理),target代表ground truth,weight代表提前计算好的类级权重。(注意注释中标注的维度信息)
在上述代码中,为了将权重w与log(p)进行元素级的相乘,先将weight按行复制了batch_size个,来让维度对齐,再将两个矩阵进行元素级的乘法,即实现了将类级的权重分别乘在了对应类的log概率前面。(也许有更简便的方法,大佬勿喷~)
接下来,为了方便的根据标签的值,从结果中取出对应标签类别的概率值,我们使用gather函数:
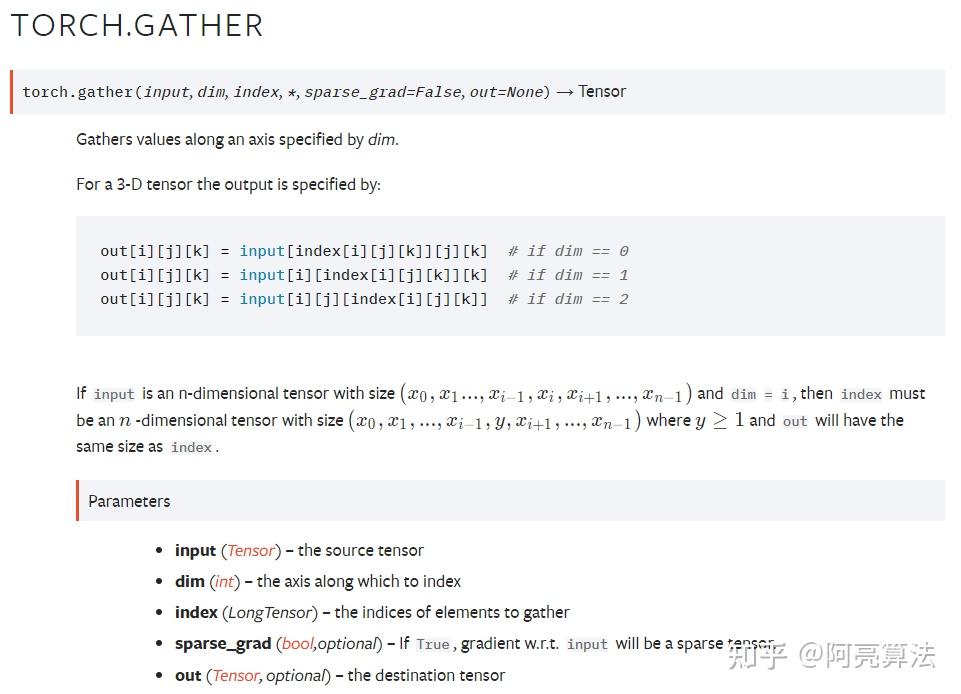
gather函数中最重要的两个参数是dim和index
dim = 1时将input看为 batch_size × 1 阶矩阵,index看为n × 1 阶(n可以是batch_size,也可以不是)矩阵,取index的每行元素对input中的每行进行列向索引(如:index某行为[1,3,0],对应的input行元素为[4,5,6,7],提取后的结果为[5,7,4]);
同样的道理,dim=0时将input看为 1 × batch_size 阶矩阵,index看为1 × n 阶矩阵,取index每列元素对input中每列进行行索引。gather函数提取后的矩阵阶数和对应的index阶数相同。
最后,对计算出的loss乘以负号,并求一个均值(有些研究可能需要求和,自行修改即可),就得到了最终类级加权的交叉熵损失值。
